


1. Introduction
It is generally accepted that null arguments in Japanese are null pronominal pro’s (e.g., ; ). Yet Oku () claims that Japanese null arguments allow interpretations that pro’s do not permit. Notice that in the strict interpretation of (1b), the pronoun it is Mary’s paper; conversely, the sloppy interpretation that it is John’s paper is not available. This example illustrates that pronouns do not permit a sloppy interpretation.
| (1) | a. | Mary thinks that her paper will be accepted. |
| b. | John also thinks that it will be accepted. |
In (2b), however, the null embedded subject [e] can be interpreted as Mary’s paper as well as John’s. If Japanese null arguments are pro’s, the embedded subject in (2b) should only allow for a strict interpretation as Mary’s paper.
| (2) | a. | Mary-wa | [zibun-no | ronbun-ga | saiyoosareru]-to | omotteiru. |
| Mary-TOP | self-GEN | paper-NOM | will be accepted-that | think | ||
| ‘Mary thinks that her paper will be accepted.’ | ||||||
| b. | John-mo | [[e] | saiyoosareru]-to | omotteiru. | ||
| John-also | will be accepted-that | think | ||||
| ‘John also thinks that [e] will be accepted.’ | () | |||||
The fact that [e] can be interpreted as John’s paper indicates that Japanese null arguments are not pro’s. Oku () argues that the sloppy interpretation results from so-called argument ellipsis (AE). Accordingly, zibun-no ronbun-ga in (2a) is copied onto [e] in (2b) at LF, leading to the sloppy interpretation, described in Section 2.
A further contrast in Japanese null arguments () is shown between (3b) and (4b).
| (3) | a. | Hanako-ga | taitei-no | sensei-o | sonkeishiteiru. | |
| Hanako-NOM | most-GEN | teacher-ACC | respect | |||
| ‘Hanako respects most teachers.’ | ||||||
| b. | Soshite | Taroo-mo | [e] | sonkeishiteiru. | ||
| And | Taroo-also | respect | ||||
| (lit.) ‘And Taroo respects, too.’ | () | |||||
| (4) | a. | Hanako-ga | taitei-no | sensei-o | sonkeishiteiru. | |
| Hanako-NOM | most-GEN | teacher-ACC | respect | |||
| ‘Hanako respects most teachers.’ | ||||||
| b. | Soshite | Taroo-mo | karera-o | sonkeishiteiru. | ||
| and | Taroo-also | them-ACC | respect | |||
| ‘And Taroo respects them, too.’ | () | |||||
The difference is that (3b) has a null object, whereas the overt pronoun karera is employed in the latter (4b). This very difference makes an interpretative difference. In (4b), when the pronoun is anaphoric to (4a), it necessarily refers to those who Hanako respects. Conversely, (3b) can also be considered as Taroo directing his respect to a different group of teachers. If the null object in (3b) is pronominal in nature, the availability of this interpretation would be surprising.
Such evidence shows that Japanese null arguments are not null pronouns. From an SLA perspective, whether AE can be learnable or unlearnable is intriguing. If such a proposition is positive, we need to determine when and how AE can be learned. Of interest is whether the availability of null pronouns in the L1 affects the (de)learning of AE in the target language. Our paper therefore addresses whether first language European speakers who are learning Japanese as a foreign language can acquire AE.
We base our theoretical assumptions on AE and pro’s: Oku’s () and Saito’s () proposal on AE based on LF-copying and Roberts’ () proposal that the presence of a D-feature in T makes pro’s available. Section 3 presents Ishino’s () feature-based approach to SLA, which claims that the L2 feature specification is to be accepted at the advanced level if the L1 lacks the feature in point; otherwise, the L1 feature specification remains. Under Ishino’s framework with recent development of syntactic theory on AE – that is, Saito () – Section 4 introduces our hypothesis on the availability of a sloppy interpretation with null arguments in the grammar of the pro-drop and non-pro-drop JFLs, followed by the experiments conducted. Section 5 discusses two findings: (i) The non-pro-drop JFLs do not permit a sloppy interpretation with null arguments even at the advanced level; we argue that this is due to the feature composition of T/v in their target language. (ii) The pro-drop JFLs permit a sloppy reading of a null argument throughout the Japanese development, consistent with claims (, ) that a sloppy reading is available with null subjects in Spanish (and Basque). Our data confirms that Spanish in fact permits AE, and then it forces us to ask how AE is allowed in their Japanese, v and T of which carry uninterpretable phi-features due to L1 transfer under Ishino’s () framework. Adopting Otaki (), we point to the presence of particles attached to nominal arguments, which behave like a clitic and enter an Agree relation with v or T. Section 6 concludes our paper.
2. Recent Syntactic Development in the Study of Null Subjects in Pro-drop Languages
2.1. Pro-drop languages: Japanese vs. Spanish
2.1.1. Oku ()
Oku’s () proposal on AE assumes that Japanese null arguments, but not Spanish null subjects (which are assumed to be pro’s), permit a sloppy interpretation. In contrast to (2b), (5b) only allows the strict interpretation.
| (5) | a. | Maria | cree | [que | su | propuesta | sera | aceptada] | y | ||
| Maria | believes | that | her | proposal | will-be | accepted | and | ||||
| ‘Maria believes that her proposal will be accepted, and’ | |||||||||||
| b. | Juan | tambien | cree | [[e] | sera | aceptada]. | |||||
| Juan | too | believe | will-be | accepted | |||||||
| (lit.) ‘Juan also believe [e] will be accepted.’ | |||||||||||
| () | |||||||||||
Here, [e] can only be interpreted as Maria’s paper. If [e] in (5b) is the covert counterpart of the pronoun it, (5b) naturally only permits the strict interpretation.
Oku () claims that only the languages that allow scrambling permit AE. Under Bošković and Takahashi’s () proposal, a ‘scrambled’ phrase is base-generated in the scrambled position, and it moves to its theta position in LF. Thus, their proposal suggests that elements can be inserted in theta positions in LF in languages (i.e., Japanese) that permit scrambling. AE, therefore, is just another instance where an element is copied from a previous sentence and inserted into a theta position in LF. In (2b), the embedded subject of (2a), zibun-no ronbun-ga, is copied to [e]. Thus, (2b) can equate with (6b) in LF, which allows the sloppy interpretation where John expects his paper to be accepted.
- (6)
- a.
- John-mo
- John-also
- [[e]
- saiyoosareru]-to
- will be accepted-that
- omotteiru.
- think
- (=(2b))
- ‘John also thinks that [e] will be accepted.’
- b.
- John-mo
- John-also
- [zibun-no
- self-GEN
- ronbun-ga
- paper-NOM
- saiyoosareru]-to
- will be accepted-that
- omotteiru.
- think
- ‘John also thinks that his own paper will be accepted.’
Oku’s proposal also accounts for the interpretation of taitei-no sensei, ‘most teachers’.
- (7)
- a.
- Hanako-ga
- Hanako-NOM
- taitei-no
- most-GEN
- sensei-o
- teacher-ACC
- sonkeishiteiru.
- respect
- (=(3a))
- ‘Hanako respects most teachers.’
- b.
- Soshite
- and
- Taroo-mo
- Taroo-also
- [e]
- sonkeishiteiru.
- respect
- (=(3b))
- ‘And Taroo respects most teachers, too.’
- c.
- Soshite
- and
- Taroo-mo
- Taroo-also
- taitei-no
- most-GEN
- sensei-o
- teacher-ACC
- sonkeishiteiru.
- respect
- ‘And Taroo respects most teachers, too.’
In (7b), taitei-no sensei, ‘most teachers’, can be copied from (7a) to [e], as (7c) illustrates. Accordingly, the group of most teachers Taroo respects does not have to be the same as those Hanako respects.
Lastly, Oku’s proposal explains the fact that Spanish does not allow AE. Spanish does not allow scrambling and thus prohibits insertion of elements in theta positions in LF; hence AE is similarly unavailable in Spanish.
2.1.2. Saito ()
Similar to Oku (), Saito () argues that AE is an instance of LF copying, but Saito proposes that an absence of phi-features correlates with the availability of AE. AE is available only in languages that do not have phi-feature agreement (). The following English examples illustrate Saito’s proposal.
| (8) | a. | John praised himself. |
| b. | *But Bill did not praise. |
In (8a), agreement occurs between the interpretable phi-features of the DP himself, and the uninterpretable ones of v, resulting in the deletion of the latter and the uninterpretable Case feature of the former. As such, (9) illustrates the series of operations.
- (9)
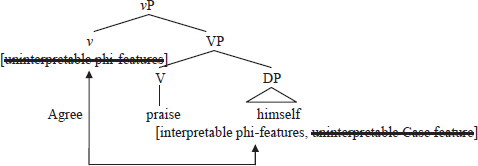
After this Agree operation, the DP himself no longer has an unvalued Case feature. This implies that the DP himself becomes inactive. Thus, given the Activation Condition (, ), which states that α can participate in Agree only if it has an uninterpretable (unvalued) feature when copied from (8a), this inactive DP cannot be a goal of v in (8b). The vP of (8b) after the copying operation in question can thus be illustrated.
- (10)

The intended Agree relation cannot therefore be established. Hence, if AE took place in (8b), the uninterpretable features of v would remain, and this example should accordingly be excluded, showing that AE should not be available in English.
Conversely, (2b) is subject to different steps of derivation, resulting from the absence of phi-features in Japanese. Here, (2a, b) are repeated as (11a, b).
| (11) | a. | Mary-wa | [zibun-no | ronbun-ga | saiyoosareru]-to | omotteiru. | |
| Mary-TOP | self-GEN | paper-NOM | will be accepted-that | think | |||
| ‘Mary thinks that her paper will be accepted.’ | |||||||
| b. | John-mo | [[e] | saiyoosareru]-to | omotteiru. | |||
| John-also | will be accepted-that | think | |||||
| ‘John also thinks that [e] will be accepted.’ | () | ||||||
In (11b), due to the absence of uninterpretable phi-features in T, the establishment of a probe-goal connected with the ‘inactive’ subject DP zibun-no ronbun, copied from (11a), is not required. This also suggests that Japanese case particles play a role different from Case features in English. For discussion, we tentatively assume that Case features are not present in (11b). Consequently, no crash occurs in (11b), as (12) illustrates.
- (12)

Consequently, the matrix subject John can be the antecedent of the anaphor zibun in (11b).
Because Spanish has phi-feature agreement, parallel to English, no AE is correctly predicted to be available. For subsequent discussion, we assume Saito’s proposal on AE, based on phi-feature agreement.
2.2. Non-pro-drop languages
Although languages such as Spanish may not allow AE, they do allow pro’s, often dubbed as pro-drop languages. Roberts () suggests pro-drop and non-pro-drop languages are distinguished by the null subject parameter, as (13) shows.
- (13)
- Does T bear a D-feature?
T does not bear a D-feature in non-pro-drop languages, whereas it does in pro-drop languages. In German, for instance, arguments cannot be null, as (14) illustrates.
| (14) | Gestern | war* | (es) | geschlossen. | ||
| yesterday | was | it | closed | |||
| ‘Yesterday it was closed.’ | () | |||||
Thus, German is classified as a non-pro-drop language, and it lacks a D-feature.
Repeating (5a, b) here as (15a, b), the embedded T is assumed to have a D-feature as well as phi-features, and thus, pro is available in (15b).
- (15)
- a.
- Maria
- Maria
- cree
- believes
- [que
- that
- su
- her
- propuesta
- proposal
- sera
- will-be
- aceptada]
- accepted
- y
- and
- ‘Maria believes that her proposal will be accepted, and’
- b.
- Juan
- Juan
- tambien
- too
- cree
- believe
- [[e]
- sera
- will-be
- aceptada].
- accepted
- (lit.) ‘Juan also thinks [e] will be accepted.’
In this example, therefore, the strict interpretation is the only available option to the embedded null subject. We therefore assume that it is the presence of a D-feature that makes pro’s available in the grammar.
3. Previous Research on Null Arguments in SLA
3.1. Resetting the pro-drop parameter in SLA
Given the pro-drop parameter, from the late 1980s onwards, the focus tended to be placed on the role of the L1 in learning or unlearning a referential null subject in L2 studies (; ; ; ; , ; ). Two important findings stem from such studies: (i) a speaker of a pro-drop language learning a non-pro-drop L2 (e.g. a Spanish speaker learning English) accepts more null subjects in their L2, though this error would gradually disappear in the course of L2 grammar development; (ii) in the opposite condition, a speaker of a non-pro-drop L1 learning pro-drop L2 (e.g., an English speaker learning Spanish) knows from a relatively early stage of acquisition that both null and overt pronouns are permitted in the L2.
Tsimpli and Roussou () contend that their L2 English learners (L1 Greek, pro-drop language) rejected English sentences involving referential null subjects not because they could acquire a correct pro-drop parameter setting of the target language, but because they misunderstood English subject pronouns as agreement elements. Namely, L2 learners kept their L1 parameter setting and applied it to L2 English. Thus, there is no equivalence between their L2 grammar and that of L1 speakers of the target language. The question therefore remains as to whether parameter resetting is possible in L2.
We believe that data from L2 Japanese learners may provide necessary information to clarify the developmental stages of null arguments of various kinds. Both Oku () and Saito () claim that Japanese null arguments are not pro but AE; it appears unsurprising if a developmental sequence in L2 Japanese grammar is not parallel to the developmental sequence of pro’s reported in such research.
3.2. Feature transfer and feature learning model ()
Recent developments in syntactic theory suggest that the target of syntactic operation does not constitute a lexical item, but rather formal features that form a lexical item. The feature-driven model of acquisition, based on the basic tenet of the minimalist program (), has enabled researchers to analyze L2 learner intuition in a more fine-grained way than the principle and parameters framework. Various feature-based proposals are entertained in the L2 literature since such a theoretical advancement. For instance, Hawkins and Chan () claim that L2 learners are restricted to L1 feature composition or specification (; ). Epstein, Flynn and Martohardjono (), Schwartz and Sprouse (), and White (), on the other hand, argue that L2 features can be acquired. Focusing on features available in UG (), Wakabayashi (, ) proposes the lexical learning and lexical transfer model (LLLT), which explains how numeration develops in L2 grammar, highlighting that L2 learner acquisition of functional features is PF (overt syntax) oriented.
A recent L2 acquisition model, the feature reassembly hypothesis (), argues that L2 learners must acquire morphological competence. Because language-specific assembly of features decides whether a form is optional or obligatory, in which domains features are marked, and so on, L2 learners need to learn L2 feature configuration. The bottleneck hypothesis (), with its main proposal that functional morphology is difficult for L2 learners, argues that L2 learners need to understand which formal features are encoded in functional morphology in the L2. Both such hypotheses state that acquiring L2 morphology is problematic for L2 learning, but they do not deny UG access in L2 acquisition.
We adopt Ishino’s () feature-based model on SLA, dubbed the feature transfer and feature learning (FTFL) model. The FTFL differs from the LLLT because the former focuses on the competition between formal features, not on numeration. Under the FTFL, L1 formal features are transferred in the early stage of L2 development, consistent with the full transfer/full access (FT/FA) hypothesis (). In the later stage, however, L2 features cannot be learned if the markedness of the specification value of L1 feature and L2 feature is identical. In this respect, The FTFL differs from the FT/FA. The FTFL essentially states that where L1 feature-transfer does occur, it does so via initial transference to the L2 grammar at the elementary-intermediate level, and that it is at the advanced level that feature specification competition occurs (i.e., features transferred at earlier stages persist at advanced level). Conversely, the absence of L1 features at earlier stages facilitates advanced level L2 feature-specification adoption; note that under the FTFL, delearning of features is not possible.
In Tables 1 and 2, ✔ and ✖ indicate the presence or absence of phi-features. For example, Japanese EFL learners are predicted to follow the steps in Table 1:
Table 1
Development of Japanese EFL Learners.
| Stages in L2 Learning | Beginner | Elementary/Intermediate | Advanced | Very Advanced |
|---|---|---|---|---|
| Feature Inventories | L1 feature Inventory | L1 feature Inventory | L2 feature Inventory | L2 feature Inventory |
| ✖ | ✖ | ✔ | ✔ | |
Table 2
Development of EFL Learners from Pro-drop (e.g. Spanish) and Non-pro-drop (e.g. English) Languages (✔* = the L1 and L2 systems are competing).
| Stages in L2 Learning | Beginner | Elementary/Intermediate | Advanced | Very Advanced |
|---|---|---|---|---|
| Feature Inventories | L1 Feature Inventory | L1 Feature Inventory | L1/L2 Feature Inventories | L1/L2 Feature Inventories |
| ✔ | ✔ | ✔* | ✔* | |
In Table 1, given that no phi-features are present in Japanese, no phi-feature specification is made for the L2 grammar at the earlier stage, and so the L2 phi-feature specification is chosen at the later stage in their grammar.
By contrast, because European pro-drop and non-pro-drop languages have phi-feature agreement, there remains this L1 setting throughout their acquisition of the target L2 regardless of whether it has phi-feature agreement, as Table 2 illustrates.
Section 2 highlights that AE is only available in languages without phi-features. Under Ishino’s framework, we predict that both pro-drop and non-pro-drop JFLs cannot learn AE in their L2 Japanese because their L1’s have phi-features, which cannot be delearned.
4. Experiment
We focus on the availability of a sloppy interpretation with null subjects and objects, used as a test to examine whether AE is available.
4.1. Hypothesis
The research questions ask whether the non-pro-drop and pro-drop JFLs will not learn AE because their L1 phi-features are not delearnable under the FTFL, based on two hypotheses, (a) and (b).
| (a) | H1: Non-pro-drop JFLs |
| If null arguments are available in their L2, the non-pro-drop JFLs will reject a sloppy reading with null arguments because they cannot unlearn their L1 phi-features. Conversely, they allow a strict reading with null arguments due to the possible insertion of D-feature (the only way they allow null argument in their L2). |
| (b) | H2: Pro-drop JFLs |
| The pro-drop JFLs will reject null arguments under a sloppy reading because they cannot unlearn their L1 phi-features. Conversely, they accept a strict reading with null arguments because of L1 transfer (of D-feature). |
4.2. Subjects
The study consisted of 54 subjects including 11 Japanese L1 speakers as our control group. The experimental groups consisted of 15 European non-pro-drop JFLs aged 19–35 (mean 24.4) and 28 pro-drop JFLs (all Spanish learners) aged 18–44 (mean 25.6). Among the 15 non-pro-drop JFLs, 12 learners were undergraduate and postgraduate students at a university in England, and three were English teachers working at a Japanese university. The pro-drop JFLs were either undergraduate students or students from a private language school in Spain. Learners were classified into four proficiency levels (i.e., SPOT or JLPT): elementary, intermediate, pre-advanced, and advanced. We set equivalent scores of each proficiency test to each level, as Table 3 shows. Table 4 summarizes the language profiles.
Table 3
SPOT and JLPT scores for each level.
| Elementary | Intermediate | Pre-advanced | Advanced | |
|---|---|---|---|---|
| SPOT | 31 ~ 55 | 56 ~ 64 | 65 ~ 80 | 81 ~ 90 |
| JLPT | N5 | N3/N4 | N2 | N1 |
Table 4
Learner-group language profiles (*11 English, 2 French, 1 German, and 1 Dutch).
| Learners group | N | Age | Level | Length of Study (year) | |
|---|---|---|---|---|---|
| non-pro-drop JFLs | 15* | 19–35 | Advanced | (n = 7) | 1–18 (mean = 5.5) |
| Pre-advanced | (n = 8) | ||||
| pro-drop JFLs | 28 | 18–44 | Pre-advanced | (n = 6) | 1–12 (mean = 3.9) |
| Intermediate | (n = 11) | ||||
| Elementary | (n = 11) | ||||
4.3. Stimuli and procedures
We administered two experimental tasks: a truth-value judgment task (TVJT), then a screening task. The task order reflects the desire to obfuscate the study focus (interpretation of null arguments) from participants.
4.3.1. Truth-value judgment task
The TVJT investigates the availability of sloppy and strict reading with null arguments. There were 52 stimuli, with 28 sentence types. The relevant sentence types to the current study, including sloppy and strict readings, involve two tokens each. Table 5 summarizes the eight stimuli, including four sentence types (see the appendix for sample stimuli). We only report the relevant data for the current study purposes.
Table 5
TVJT sentence types.
| Argument | Context | |
|---|---|---|
| Null subject | sloppy | (n = 2) |
| Null subject | strict | (n = 2) |
| Null object | sloppy | (n = 2) |
| Null object | strict | (n = 2) |
For each stimulus, there was a dialogue among or between different animal figures; the images of the animal figurines with the corresponding audio recording of the dialogue were shown and played concurrently. Recordings were in two languages, English and Spanish. English recordings were played to the non-pro-drop JFLs; Spanish recordings were for the pro-drop JFLs (because all of them were Spanish learners). All participants were introduced to Elmo, a character who had just started learning Japanese. Elmo then proceeded to explain the contents of each dialogue after it was played. JFLs were required to judge Elmo’s accuracy by circling ‘Correct’ or ‘Incorrect’. Sample test items are in (16) and (17). Here, (E) refers to the English dialogues for the non-pro-drop JFLs, and (S) is the Spanish version. The instrument for the non-pro-drop learners is the same one used in our earlier paper ().
| (16) | Sloppy interpretation | |
 | (English) My car is very dirty. I should clean it. (Spanish) Mi coche está muy sucio. Debería lavarlo. | |
 | (E) It’s very clean now. (S) Está muy limpio ahora. | |
 | (E) I should clean the car, too. (S) Debería limpiar el coche también. | |
 | (E) Now, it is very clean. (S) Ahora está muy limpio. | |
| Test sentence: | |||||||||
| Elmo: | Kuma-wa | jibun-no | kuruma-o | fuita. | Sosite, | Pengin-mo | [e] | fuita. | |
| Bear-TOP | self-GEN | car-ACC | wiped | and | penguin-also | wiped | |||
| ‘Bear wiped his own car, and Penguin wiped [e], as well.’ | |||||||||
| Correct/Incorrect | |||||||||
| (17) | Strict interpretation | ||
 | (E) | Bear: Let’s clean the car. | |
| Penguin: I will help you. | |||
| (S) | Oso: Vamos a lavar el coche. | ||
| Pingüino: Te ayudaré. | |||
 | (E) | Bear: Now, it is really clean. Thank you very much, Penguin. | |
| Penguin: You’re welcome. | |||
| (S) | Oso: Ahora está realmente limpio. Muchas gracias, Pingüino. | ||
| Pingüino: De nada. | |||
| Test Sentence | |||||||||
| Elmo: | Kuma-wa | jibun-no | kuruma-o | fuita. | Sosite, | Pengin-mo | [e] | fuita | |
| Bear-TOP | self-GEN | car-ACC | wiped | and | penguin-also | wiped | |||
| ‘Bear wiped his own car, and Penguin wiped [e], as well.’ | |||||||||
| Correct/Incorrect | |||||||||
In order to avoid ordering effects, two versions of the test were created for each learning group, with the same experimental items distributed in a different sequence. The learners then had to take their assigned version of the test. Instructions to the learners included not skipping any questions and not changing their answers once chosen.
Each dialogue was recorded by two L1 English speakers, two L1 Spanish speakers, and Elmo’s Japanese sentences by one L1 Japanese speaker.
4.3.2. Screening task
The screening task allowed identification of subjects where null arguments were present in the L2. In the main study (the TVJT), we expected the JFLs to judge whether a null argument could have either a sloppy reading or a strict reading. Therefore, it was indispensable for the JFLs to know that null arguments are available in their L2. The test consisted of six stimuli: three included null subjects, and three included null objects. Sample test items are in (18) and (19). The test for the non-pro-drop learners is the same one conducted as in our earlier paper (see ).
| (18) | Null subject | |||||||||||||
| Taroo-ga | akai | huku-no | onna-no | hito-o | mita | toki, | [e] | sono | hito-o | Sam-no | oneesan | da-to | omoimashita. | |
| Taro-NOM | red | clothes-NOM | woman-GEN | person-ACC | saw | when, | that | person-ACC | Sam-GEN | elder sister | is-that | thought | ||
| ‘When Taro saw a lady wearing red clothes, [e] thought she was Sam’s elder sister.’ | ||||||||||||||
| natural/acceptable or unnatural/unacceptable | ||||||||||||||
| (19) | Null object | ||||||
| Taroo-ga | kompyuutaa-o | kowashi-te shimaimashita | ga, | otoosan-ga | [e] | naoshimashita. | |
| Taro-NOM | computer-ACC | ended up breaking | although | father-NOM | fixed | ||
| ‘Although Taro broke a computer, his father fixed [e].’ | |||||||
| natural/acceptable or unnatural/unacceptable | |||||||
The subjects were also asked to correct sentences judged unnatural/unacceptable. Although not subject to strict timing, the JFLs were requested to answer promptly, and to remain consistent in their answers from previous items.
4.4. Results
4.4.1. The non-pro-drop JFLs
The data from the screening task were analyzed first because only the non-pro-drop JFLs who permitted null arguments in their L2 were taken into consideration in analyzing the data from the TVJT. The screening task facilitated benchmarking through identifying learners that had allowed a null argument (once or more) in both subject and object positions for inclusion in the study. All the 15 non-pro-drop JFLs met our standard; we included learners who accepted at least one sentence from the three with null subject argument and accepted at least one sentence from the three with a null object argument. Conversely, subjects were excluded from analyses in cases where learners rejected all six sentences with a null subject or null object. Subjects were also excluded in cases where learners allowed only a sentence with a null subject argument or only a sentence with a null object argument.
Regarding the TVJT, Figures 1 and 2 summarize the results of the non-pro-drop JFLs. L1 Japanese speakers permitted null arguments to have both sloppy and strict interpretations in both subject and object positions (about 77–100%). Their results confirm that the Japanese test sentences with null arguments Elmo uttered were acceptable. Both pre-advanced and advanced non-pro-drop JFLs rejected a sloppy interpretation with null arguments while they accepted a strict interpretation. As Figure 1 shows, the non-pro-drop JFLs accepted null subjects with sloppy interpretation only about 20–25% whereas the acceptance rate of null subjects with strict interpretation was greater than 85%. This contrast in acceptance between sloppy and strict interpretations is also observed in object position. As Figure 2 indicates, the non-pro-drop JFLs permitted null objects with sloppy interpretation about 30% of the time. Conversely, higher acceptance rates of null objects with strict interpretation were observed: 62.5% for the pre-advanced learners and 78.6% for the advanced.
Non-pro-drop JFLs’ acceptance rate- null subject items judged appropriate on the TVJT.
Non-pro-drop JFLs’ acceptance rate- null object items judged appropriate on the TVJT.
An ANOVA confirmed that there is a highly significant main effect for the two conditions: null subject sloppy (F(2, 23) = 21.51, p < 0.001) and null object sloppy (F(2, 23) = 27.51, p < 0.001). The results of the multiple comparison showed a highly significant difference in acceptance rates between the Japanese natives and the two proficiency groups (p < 0.001 for each condition), while no significant difference was found between the advanced and the pre-advanced JFLs (p = 0.76 for null subject sloppy, p = 0.96 for null object sloppy). Thus, the non-pro-drop JFLs’ sloppy interpretation differs from the native speakers, and both proficiency JFL groups disallowed null arguments with sloppy reading in the same way.
Of interest are the results of three non-pro-drop JFLs working in a Japanese university. The tokens in gray are from the three JFL responses in Table 6. Because they had been resident in Japan for longer than five years, they had greater exposure to Japanese than the other 12 non-pro-drop JFLs, but their interpretation did not differ from other 12 JFLs. Table 7 summarizes the three JFLs results. These three non-pro-drop JFLs allowed a strict interpretation 100% of the time in both subject and object positions, but they rejected a sloppy interpretation in both positions around 85% of the time. These figures indicate that there is still a great difference in intuition on a sloppy interpretation between these three learners and the L1 speakers of the target language.
Table 6
Individual acceptance on the TVJT (token).
| Non-pro-drop JFLs (n = 15) | Null subject sloppy | Null subject strict | Null object sloppy | Null object strict |
|---|---|---|---|---|
| Advanced 1 | 0 | 2 | 0 | 2 |
| Advanced 2 | 1 | 1 | 1 | 1 |
| Advanced 3 | 0 | 1 | 0 | 0 |
| Advanced 4 | 1 | 2 | 1 | 2 |
| Advanced 5 | 0 | 2 | 1 | 2 |
| Advanced 6 | 1 | 2 | 1 | 2 |
| Advanced 7 | 0 | 2 | 0 | 2 |
| Pre-advanced 1 | 1 | 2 | 1 | 1 |
| Pre-advanced 2 | 1 | 2 | 0 | 1 |
| Pre-advanced 3 | 0 | 1 | 0 | 1 |
| Pre-advanced 4 | 0 | 1 | 0 | 1 |
| Pre-advanced 5 | 2 | 2 | 2 | 1 |
| Pre-advanced 6 | 0 | 2 | 1 | 1 |
| Pre-advanced 7 | 0 | 2 | 1 | 2 |
| Pre-advanced 8 | 0 | 2 | 0 | 2 |
Table 7
Three English Teachers’ acceptance rate- null arguments judged appropriate on the TVJT.
| Null subject sloppy | Null subject strict | Null object sloppy | Null object strict |
|---|---|---|---|
| 16.7% | 100% | 16.7% | 100% |
Finally, Table 8 shows an item analysis, conducted because of the relatively small number of items (i.e., two items) per condition in our experiment. No preference was observed between the two items in each condition, as the shaded columns indicate.
Table 8
Descriptive item analysis (non-pro-drop JFLs (n = 15)).
| Condition | Level | Acceptance | N | Item 1 | Item 2 | |
|---|---|---|---|---|---|---|
| Null Sub sloppy | Advanced | (n = 7) | 21.5% | 3/14 | 2 | 1 |
| Pre-advanced | (n = 8) | 25.0% | 4/16 | 3 | 1 | |
| Null Sub strict | Advanced | (n = 7) | 85.7% | 12/14 | 7 | 5 |
| Pre-advanced | (n = 8) | 87.5% | 14/16 | 8 | 6 | |
| Null Obj sloppy | Advanced | (n = 7) | 28.6% | 4/14 | 1 | 3 |
| Pre-advanced | (n = 8) | 31.3% | 5/16 | 3 | 2 | |
| Null Obj strict | Advanced | (n = 7) | 78.6% | 11/14 | 6 | 5 |
| Pre-advanced | (n = 8) | 62.5% | 10/16 | 3 | 7 | |
For the non-pro-drop JFLs, even at the advanced level, their percentages of sloppy reading acceptance were low, although null arguments are available in their L2 grammar. As above, however, the non-pro-drop JFLs did not completely reject a sloppy reading. They might potentially have permitted null arguments with an indefinite-NP reading (). Namely, in the sentence ‘Bear wiped his own car, and Penguin wiped [e], as well’, given in a sloppy context, Penguin also wiped a car, but the car is irrespective of whose car it is – Penguin wiped any car. Moreover, a t-test confirmed that there was a highly significant difference between acceptance rates for null subject sloppy and strict (p < 0.001) and a significant difference in null object sloppy and strict (p < 0.01), indicating that they could not acquire AE in Japanese, which supports our prediction.
4.4.2. The pro-drop JFLs
Regarding the screening task results, again a benchmark was set: when a null subject and null object were permitted even once each in their L2 Japanese, the JFLs were included in our study. All the pro-drop JFLs were included in our main study as they met the benchmark.
Figures 3 and 4 summarize the TVJT results of the pro-drop JFLs. Figures 3 and 4 show that unlike the non-pro-drop JFLs’ results, no clear contrast in the acceptance rate between sloppy and strict interpretations. The pro-drop JFLs from all the three levels accepted both sloppy and strict interpretations with null subjects and null objects. Null subjects are permitted with sloppy interpretation from 63.6–86.4%. These acceptance rates are like the acceptance rates of null subjects with strict interpretation, 75–86.4%. Figure 4 shows high acceptance rates in object position, 66.7–81.8% for sloppy interpretation and 66.7–77.3% for strict interpretation.
Pro-drop JFLs’ acceptance rate- null subject items judged appropriate on the TVJT.
Pro-drop JFLs’ acceptance rate- null object items judged appropriate on the TVJT.
The elementary group performed better on a sloppy reading than the pre-advanced group in both null subject and null object. One potential reason might be that, like the pre-advanced non-pro-drop JFLs, the elementary pro-drop JFLs allowed null arguments with an indefinite-NP as well as a sloppy reading. The acceptance rates of null subject and null object arguments in both sloppy and strict readings do not differ between the proficiency levels. An ANOVA confirmed that there is no significant main effect for each condition: null subject sloppy (F(3, 35) = 1.71, p = 0.18), null subject strict (F(3,35) = 0.25, p = 0.86), null object sloppy (F(3, 35) = 1.91, p = 0.15), and null object strict (F(3, 35) = 0.15, p = 0.93). Thus, the acceptance rate of each condition does not differ between the four groups, including the Japanese natives.
Finally, an item analysis, conducted due to relatively small number of items per condition in our experiment, is shown in Table 9. No preference was observed between the two items in each condition, as the shaded columns indicate.
Table 9
Descriptive item analysis (pro-drop JFLs (n = 28)).
| Test condition | Level | Acceptance | N | Item 1 | Item 2 | |
|---|---|---|---|---|---|---|
| Null Sub sloppy | Pre-advanced | (n = 6) | 75.0% | 9/12 | 4 | 5 |
| Intermediate | (n = 11) | 63.6% | 14/22 | 6 | 8 | |
| Elementary | (n = 11) | 86.4% | 19/22 | 10 | 9 | |
| Null Sub strict | Pre-advanced | (n = 6) | 75.0% | 9/12 | 5 | 4 |
| Intermediate | (n = 11) | 81.8% | 18/22 | 9 | 9 | |
| Elementary | (n = 11) | 86.4% | 19/22 | 10 | 9 | |
| Null Obj sloppy | Pre-advanced | (n = 6) | 66.7% | 8/12 | 3 | 5 |
| Intermediate | (n = 11) | 77.3% | 17/22 | 8 | 9 | |
| Elementary | (n = 11) | 81.8% | 18/22 | 9 | 9 | |
| Null Obj strict | Pre-advanced | (n = 6) | 66.7% | 8/12 | 4 | 4 |
| Intermediate | (n = 11) | 77.3% | 17/22 | 7 | 10 | |
| Elementary | (n = 11) | 72.7% | 16/22 | 8 | 8 | |
These results indicate that the pro-drop JFLs in our study allow a sloppy interpretation in their L2 Japanese. Although their L1 Spanish has phi-feature agreement, the pro-drop JFLs have a good AE command.
5. Discussion
Our results confirm predictions for the non-pro-drop JFLs. These subjects maintain their L1 feature setting until the advanced level, and given the assumption that delearning of features is not possible in the L2, AE cannot be acquired. The only way they allow null arguments in their L2 Japanese is by adding a D-feature to their L2 feature bundles, suggesting that null arguments in their L2 are pro’s, in turn permitting only a strict interpretation.
The results for the pro-drop JFLs, however, need examining in order to establish why a sloppy interpretation, as well as a strict interpretation at all levels, can be permitted. If Spanish only allows pro’s, as Oku () claims, this result is unexpected. It is difficult under Oku’s and Saito’s proposal, if not impossible, for the fact that the pro-drop JFLs permitted not only strict but also sloppy interpretation, if their null elements are uniformly pro’s.
For Ishino, the current result indicates that positive L1 transfer must have taken place; Spanish should allow AE despite it having phi-features. We thus conclude that it allows AE in some well-defined contexts. To clarify, we turn to Duguine (, ) data showing that Spanish null subjects in fact permit a sloppy interpretation. Consider (20b), following (20a).
| (20) | a. | Maria | cree | [que | su | trabajo | le | exigirá | mucho | tiempo]. |
| Maria | believes | that | her | work | CL.1sg.DAT | require.FUT.3sg | much | time | ||
| ‘Maria believes that her job will require a lot of time from her.’ | ||||||||||
| b. | Y | Ana | espera | [que | [e] | le | dejará | los | fines | de | semana | libre]. | |
| and | Ana | hopes | that | CL.1sg.DAT | leave.FUT.3sg | the | ends | of | week | free | |||
| (lit.) ‘And Ana hopes [e] will leave her the weekends available.’ | |||||||||||||
| () | |||||||||||||
The sentence in (20b) can mean that Ana hopes her own work will leave her the weekends available.
Examples such as (20b) allow a sloppy reading, and so we ask how Spanish allows AE, given that it has phi-feature agreement. One obvious difference between (20a, b) and Oku’s examples in (5), repeated here as (21), is that in the former, the clitic acts as the local binder of the covert subject.
| (21) | a. | Maria | cree | [que | su | propuesta | sera | aceptada] | y |
| Maria | believes | that | her | proposal | will-be | accepted | and | ||
| ‘Maria believes that her proposal will be accepted, and’ | |||||||||
| b. | Juan | tambien | cree | [[e] | sera | aceptada]. | ||
| Juan | too | believe | will-be | accepted | ||||
| (lit.) ‘And Ana hopes [e] will leave her the weekends available.’ | ||||||||
| () | ||||||||
To capture the contrast between (20b) and (21b), we assume under Saito () that uninterpretable phi-features on T enter into an Agree relationship with interpretable phi-features of a clitic, and thus are valued (; ; ). In (20b), we assume that the following Agree relation is established.
- (22)

Accordingly, no phi-feature agreement needs to be established between the null subject [e] and T in this case. Even if the DP without any uninterpretable Case feature is copied from the previous sentence, no issue arises with the uninterpretable phi-features of T. In short, Spanish permits AE when the local binder for the covert argument is present, suggesting that examples like (20b) do not refute Oku () and Saito (); rather, their proposals capture the contrast between (20b) and (21b).
To the extent that the availability of a sloppy interpretation is tied to the presence of a clitic in Spanish, their L2 Japanese, which is assumed to have phi-feature agreement due to L1 transfer, should include an element acting like a clitic for phi-feature Agree, so that AE also becomes available in their interlanguage. Which element acts like a clitic in this manner in their L2 Japanese (as no overt clitic is present in their target L2) needs clarifying.
We believe that Otaki’s () proposal on AE provides a clue to answer this specific question. Extending Neeleman and Szendrői’s () proposal on the cross-linguistic distributional difference of null pronouns, Otaki claims that AE is available only in languages with non-fusional, agglutinating case morphology, or only languages with case markers permitting AE. Having case markers such as nominative -ga and accusative -o, Japanese is one such language, and so Otaki correctly predicts that Japanese allows AE. By way of contrast, German, is a fusional language, which can be seen in that definite determiners change their form depending on the gender and number: for example, der (masculine, singular), das (neuter, singular), die (feminine, singular), die (plural). Consequently, AE is not available in German, as (14) illustrates, repeated as (23).
- (23)
- Gestern
- yesterday
- war
- was
- *(es)
- it
- geschlossen.
- closed
- (=(14))
- ‘Yesterday it was closed.’
Let us illustrate how Otaki’s proposal works with the German and Japanese examples in (24a, b).
- (24)
- a.
- der
- the (nominative, masculine, singular)
- Vater
- father
- b.
- chichi-ga
- father-NOM
First, (24a) is assumed to have the structure given in (25).
| (25) |  | |
| () |
In (25), K and # are assumed to form a single node and are realized as /er/. In addition, due to morphological merger, /er/ and /d/ create /der/. Thus, we can interpret that the morphological requirement illustrated here requires the presence of #P in PF: unless its presence is guaranteed in overt syntax, it cannot be an instruction for the morphological operation in point. Accordingly, the #P cannot be copied from a previous discourse element in LF. Conversely, we know that Japanese particles can stand alone, given sufficient context. Consider examples from Sato and Ginsburg ().
- (26)
- A:
- Asami-wa
- Asami-TOP
- moo
- already
- tsukimashita
- arrived
- ka.
- Q
- ‘Has Asami already arrived?’
- B:
- Hai,
- yes
- moo
- already
- tsukimashita.
- arrived
- ‘Yes, she has already arrived.’
- A:
- Naomi-mo
- Naomi-also
- moo
- already
- tsukimashita
- arrived
- ka.
- Q
- ‘Has Naomi also already arrived?’
- B:
- [e]
- ga
- NOM
- mada
- yet
- tsukimasen.
- not arrived
- ‘She has not arrived yet.’
According to Otaki, this #P ellipsis is possible in Japanese because K does not have to undergo the morphological merger that is required in German.
In German, KP itself cannot be the target of ellipsis, either. The KP, which is to be copied from a previous discourse element, is inactive in the sense that it does not retain its uninterpretable Case feature. Accordingly, T/v’s uninterpretable phi-features will not be valued and remain, and its derivation crashes. Conversely, given the assumption that the presence of a Case particle means the presence of an uninterpretable case feature, Japanese KP remains active. Consequently, after the LF-copying of the relevant #P with interpretable phi-features, the T/v, the Agree relation illustrated in (27) should be possible.
- (27)

Following Otaki’s () proposal on Japanese AE, we speculate that the pro-drop JFL learners take case particles as a holder of an uninterpretable Case feature for phi-feature Agree, and thus, AE is available in their L2 Japanese.
6. Concluding Remarks
The current paper reports on experimental data showing that AE is not available to the non-pro-drop JFLs at an advanced level, given the assumption that the non-pro-drop JFLs have added a D-feature to the feature bundles to make null elements available. This feature concatenation, however, only allows pro’s, which do not permit a sloppy interpretation. The results from the pro-drop JFLs are surprising for Oku’s () and Saito’s () approach to AE. Conversely, our results are consistent with Duguine (, ). Following Otaki (), we speculate that the pro-drop JFLs take Japanese case particles as a holder for uninterpretable Case features. If our speculation proves to be correct, the contrast between the European pro-drop and non-pro-drop JFLs remains under scrutiny within Ishino’s () feature-based framework on SLA.
Additional File
The Additional file for this article can be found as follows:
AppendixSample stimuli: Truth-Value Judgment Task. DOI: https://doi.org/10.22599/jesla.18.s1